核心论点:速度本身正在变成能力
文章的主线很清楚:大模型推理系统过去先解决“模型能不能跑起来”,后来追求“单位成本下吞吐更高”,现在进入第三阶段:实时 AI 交互要求低延迟,速度开始直接影响用户体验和模型能力。
在 Agent、语音、代码补全、工具调用和 Test-Time Scaling 场景里,系统不只要“最终生成很多 token”,还要在固定延迟预算内更快地产生下一步反馈。推理越快,Agent 能做的 rollout 越多,搜索越深,自验证越充分,交互越自然。
吞吐优先
适合离线批量或请求充足的场景。大 batch、深队列、多级 KV cache 能摊薄固定开销。
延迟优先
适合实时交互。用户关心下一次响应是否足够快,固定开销无法再被大批量掩盖。
能力优先
在 Test-Time Scaling 下,速度决定同一时间内能探索多少路径,直接影响推理深度。
性能鸿沟:硬件很强,但 token 还不够快
文章给了一个非常直观的落差:8×H200 NVL 服务器聚合内存带宽接近 38 TB/s;对 GLM-5.1 来说,单次 decode 实际激活参数量约 42GB。只从理论带宽估算,不启用 MTP 时 token 生成速度理论上接近 1000 token/s。
但真实系统里的端到端速度常常只有几十 token/s。差距不在于 GPU 完全没有算力,而在于算力被一道道执行边界切碎。
| 表面现象 | 更深层原因 | 为什么影响低延迟 |
|---|---|---|
| GPU 利用率不低,但 token 延迟仍高 | 执行边界多,流水线不连续 | GPU 在反复等待下一段工作开始 |
| 单个 kernel 看起来已经很快 | kernel 之间 launch、barrier、同步开销高 | 微秒级 decode 会放大固定开销 |
| 计算和通信无法充分重叠 | 通信仍作为独立阶段存在 | 同步点进入关键路径,尾延迟变差 |
| 真实流量比 benchmark 慢 | 上下文长度、KV cache、路由、MTP 路径都动态变化 | 理想流水线在生产负载下破碎 |
文章把这个问题称为 execution gap:真正吞噬延迟的,常常不是某个 GEMM 不够快,而是算完这一段之后,下一段什么时候才能无缝开始。
TileRT 的方向:从离散 kernel 到常驻执行流水线
传统推理框架把模型拆成一串 operator,每个 operator 启动自己的 kernel,执行后写回,再同步,再启动下一个。这种模式在训练或大 batch 推理中合理,因为大 kernel 可以掩盖固定开销。
但 TileRT 的判断是:当 runtime scheduling 本身进入延迟关键路径,就不能只继续优化 runtime,而要重构执行模型。
Persistent Execution
TileRT 会在编译期把整个模型静态展开为一个常驻 Engine Kernel。GPU 不再不断被 host runtime 驱动去启动一串 kernel,而是在 decode 生命周期里维护一条长期运行的任务流水线。
Tile-Level Pipeline
TileRT 把计算、通信、异步 IO 统一拆成 tile-level task,在 GPU 内部持续推进。大量中间结果不再反复写回 global memory,而是尽量留在 register、shared memory 和 L2 cache 中继续向后流动。
Warp / Block Specialization
不同 warp group 承担不同职责:有的负责数据搬运,有的负责张量计算,有的负责同步或通信推进。过去串行的 load → barrier → compute → barrier,被改造成更连续的重叠执行。
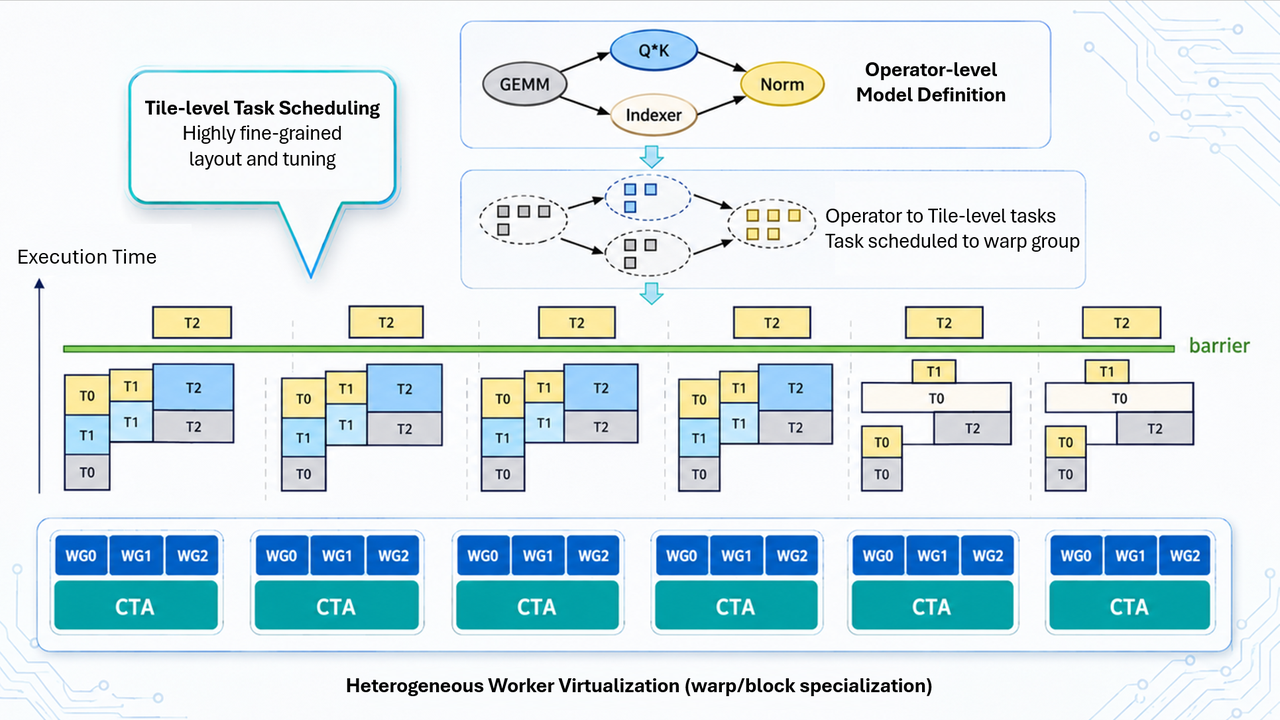
从 Warp Specialization 到 Heterogeneous Worker
单卡内部通过 persistent kernel 和 tile pipeline 能压缩大量执行空泡。但扩展到 8×NVL 后,文章指出另一个边界出现了:同构张量并行并不总适合低延迟推理。
传统 TP 默认所有 GPU rank 执行相同逻辑,通过同步共同推进。但 GLM-5.1 这类模型里,稀疏路由、Top-K 选择、动态索引、长上下文 attention、MTP 执行等阶段并不天然适合同构扩展。
warp specialization → block specialization → GPU specializationTileRT 于是把 specialization 从 SM 内部扩展到整个 NVL 域:不同 GPU 不再被视为完全对称的执行单元,而是根据计算密度、通信成本和数据依赖承担不同职责。
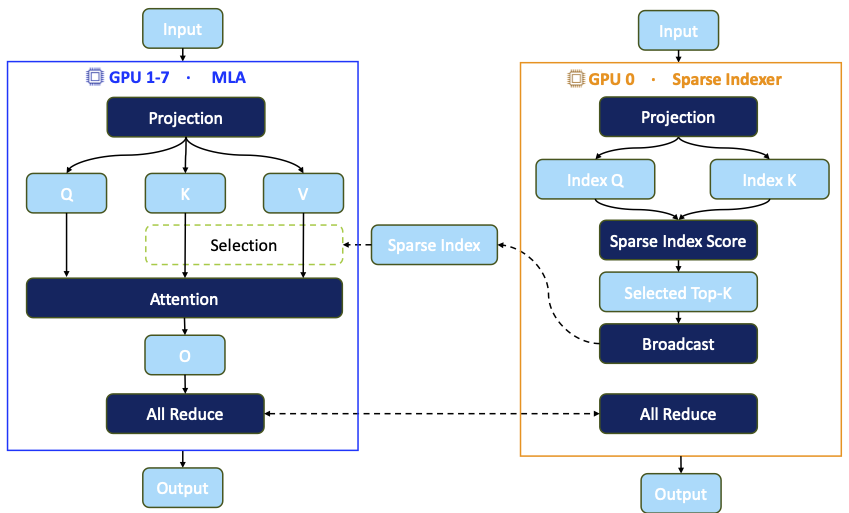
| Worker 类型 | 负责内容 | 为什么要拆开 |
|---|---|---|
| 稀疏索引 Worker | Top-K 选择、稀疏索引构建、路由决策 | 更依赖全局信息和同步,集中执行更合理 |
| MLA Worker | RMSNorm、GEMM、Flash Sparse Attention、AllReduce 等 | 计算密集,更适合张量并行和重叠执行 |
这一步的关键不是简单分工,而是让不同 execution stage 拥有不同扩展策略。通信也不再作为执行流之外的独立阶段,而是进入 tile flow 内部。
过去:compute → sync → compute
现在:compute ↔ communication ↔ compute生产化:真正难的是持续跑得快
文章反复强调,极致 benchmark 往往很脆弱。实验室里跑出漂亮数字相对容易,难的是在真实生产流量下持续接近硬件上限。
v0.1.1
进一步压缩执行流水线空泡,引入更细粒度 overlap,改善端到端延迟和 tail latency。
v0.1.2-alpha.1
MTP 进入执行流。挑战不只是一次生成更多 token,而是 accept / reject path 会让 pipeline 动态变化。
v0.1.3
支持 GLM-5,FP8 与超长上下文进入生产,KV cache 压力、访存局部性和通信放大成为关键。
文章预告 v0.1.4 会进一步面向超长上下文生产环境,并引入新的 Heterogeneous Worker 执行模型。它的目标不是只在理想条件下跑出峰值,而是在真实流量、动态路径、长上下文和复杂通信模式交织时仍保持执行流不断。
下一阶段:模型、编译器、硬件重新耦合
过去很多优化发生在算子和 kernel 层:更快 GEMM、更激进融合、更高效通信 overlap、更复杂调度策略。但当系统接近硬件边界,瓶颈会变成结构性边界。
| 旧模式 | 问题 | 新方向 |
|---|---|---|
| model → compiler → hardware | 模型先设计出来,系统工程师再补救性能问题 | 模型结构、编译器、runtime、硬件共同设计 |
| 局部 operator 优化 | 无法解决执行流碎片、同步膨胀、通信放大 | 优化整条任务流水线 |
| runtime 驱动 GPU | host 调度进入延迟关键路径 | 更多编排逻辑下沉到 GPU 内部 |
文章最后的判断是:推理系统会从“算子优化”演化为真正的 AI execution infrastructure。速度不只是体验指标,而会影响推理深度、交互质量、Agent 响应能力和模型在固定时间预算内能做多少工作。
我的整理:这篇文章最值得记住的 8 件事
- 速度不是锦上添花,实时 AI 里速度会变成模型能力的一部分。
- 吞吐优先的推理框架,不能天然解决低延迟交互问题。
- 真实瓶颈常常不在某个 kernel 内部,而在 kernel 与 kernel 之间。
- TileRT 的核心不是“又一个更快 kernel”,而是常驻执行流水线。
- Tile-level pipeline 的价值是让计算、通信、IO 更连续地重叠。
- Heterogeneous Worker 把 specialization 从 warp 扩展到 GPU 级别。
- MTP 和长上下文让执行流变得动态,系统必须维护 execution continuity。
- 未来极致推理性能需要模型、编译器、runtime、通信和硬件协同设计。